Manage Your Memory in Stata
When you load a dataset into Stata, it keeps the data in memory. This makes Stata fast and safe for user interaction. However, when you add variables derived from other variables, the dataset can become larger. As the dataset expands, it will still need to fit in to the available memory. When dealing with expanding datasets you may want to reduce the size of your dataset to reduce the amount of memory used. Today I would like to introduce three methods to reduce the size of your datasets in Stata. The dataset I used is automobile dataset.
NOTE: Please make sure that the file must either be in the present working directory, or you will need to specify the full path when using the dataset. To demonstrate, I will specify the full path in every example.
Method 1: The compress command
You can use compress with a varlist, to specify certain variables. If you do not give a varlist, it acts on all the variables. The compress command works on both string and numeric variables.
NOTE: Stata will not reduce the precision of your data by compressing the data.
Let’s pretend that the automobile dataset is extremely large with several thousand variables:

Memory compression is usually only a concern when you are dealing with very big datasets. However, when importing a new dataset it is always a good idea to run the compress command so that your dataset is taking up as little RAM as possible, leaving as much RAM as possible for faster processing.
Method 2: The use command with if and in qualifiers
Another way to manage your memory is to only load the necessary variables and/or observations into Stata. Sometimes a dataset can have thousands of variables and billions of observations. You may only care about a few variables or a range of observations for your analysis. Using if and in qualifiers with the command use is an effective way to load only the data you really need.
Again, let’s pretend that the automobile dataset is extremely large with several thousands variables, but for our analysis, we may only want the variables mpg and weight. To load just these two variables on a Windows computer, replace VR with your current Stata version number in the below command:
use mpg weight using "C:\Program Files\StataVR\ado\base\a\auto.dta", clear
If you are using a Mac, the code is:
use mpg weight using "/Applications/Stata/auto.dta", clear
Method 3: The describe command
If you are not sure which variables you want to load into memory, before you choose the variables, it is possible to explore a dataset without loading it into memory. The describe command allows you to do exactly that. I will use the automobile dataset to demonstrate how to use this command. We can see from the below output that Stata gives you the storage type for all the variables:
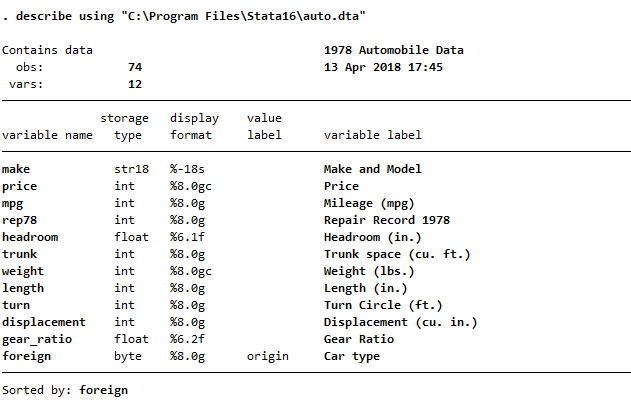
If your dataset has thousands of variables, you might need to subset the variables list. For example, in the automobile dataset, if I would like to know just the variables that start with “t”, I would type:
describe t* using "C:\Program Files\StataVR\ado\base\a\auto\auto.dta"
If you are using a Mac, the code is:
describe t* using "/Applications/Stata/auto.dta"
NOTE: It is also possible to use the “Open data subset …” option from the File menu in Stata. This will allow you to select a Stata dataset and a pop-up dialog box will give you a preview of the dataset. This is similar to the previews you can see when using the menus to import an excel spreadsheet.