Subsetting Data - Speeding Up your Processing Time
Some data sets can be huge and unwieldy, slowing down processing time. Typically, only a portion of the data is needed. If the end user can identify the variables they need, they can select their required slice of data and just operate on this set, rather than importing everything. This is called subsetting your data, so you are only working on the part you are interested in. There are two ways to subset your data.
First, you can use the keep and drop commands to subset variables, once the data file is loaded into Stata.
Second, you can use the use command, which will only import the subset of data to begin with (without having to bring the entire datafile into Stata first). This does rely on the user being familiar with the variable names, and using a Stata data set (.dta).
How to Use:
Using the keep and drop commands
To keep specific variables (deleting the rest) or drop (delete) specific variables
keep var1 var2 var3
drop var4 var5 var6
To keep specific observations (deleting the rest), or drop (delete) specific observations
drop if var1>10
keep if var1 <=10
Using the use command (requires some knowledge if the data you are importing)
use var1 var2 var3 using "C:\Users\Username\Documents\filename.dta"
use "C:\Users\Username\Documents\filename.dta" if (var1<=10 & var2>20)
These are similar to the keep option, as you are telling Stata which variables you want to load in to the exclusion of everything else.
The file path that you specify can be on your computer hard drive, on a server or external hard drive your computer is connected to, or a dataset off the internet. An example of each of these would be:
Worked Example 1:
In this example I will demonstrate using the keep and drop commands to subset your data. Let’s use the auto dataset for this example. In the command pane I type the following:
sysuse auto, clear
describe
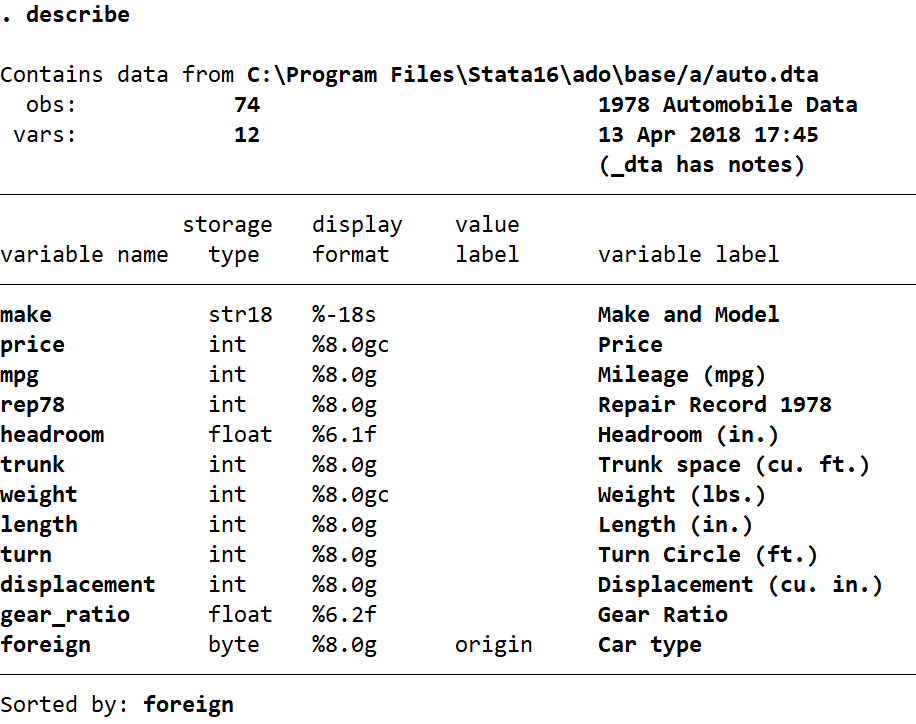
drop weight length turn displacement gear_ratio foreign
OR the following keep command is equivalent to the drop command above
keep make price mpg rep78 headroom trunk
Now we describe the dataset again to see what has changed.
describe

Here I have removed six variables (weight, length, turn, displacement, gear_ratio and foreign), with the rest remaining in Stata.
In the data above you can see that the variable “rep78” has some missing values. I don’t want any of my observations (rows) to include missing values, so I am going to remove them. In the command pane I type the following:
drop if missing(rep78)
OR alternatively
drop if rep78==.
Then we use the describe command to have another look at our dataset.
describe
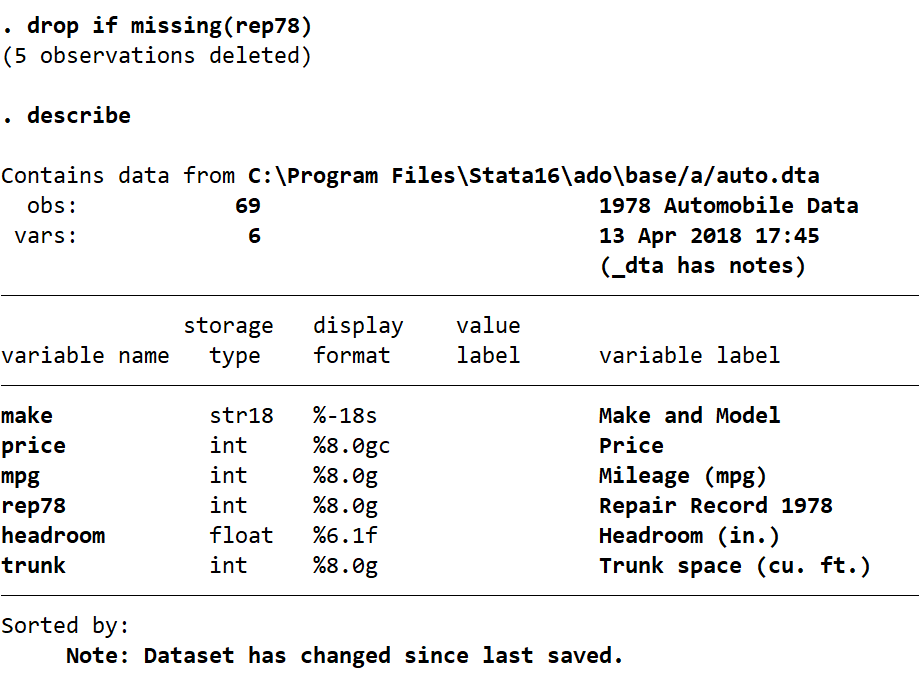
When we drop observations from a dataset Stata lets us know how many have been deleted. In this case we have deleted 5 observations (rows) from our dataset. However, if we didn’t have this information we could still see that some observations had been lost. We simply compare the number of observations in this describe summary (obs: 69) with the number of observations in the previous describe summary (obs: 74).
Finally, I am only interested in cars that cost $6000 or less, so I am going to remove all the cars that cost more than this from the dataset. In the command pane I type the following:
drop if price>6000
describe
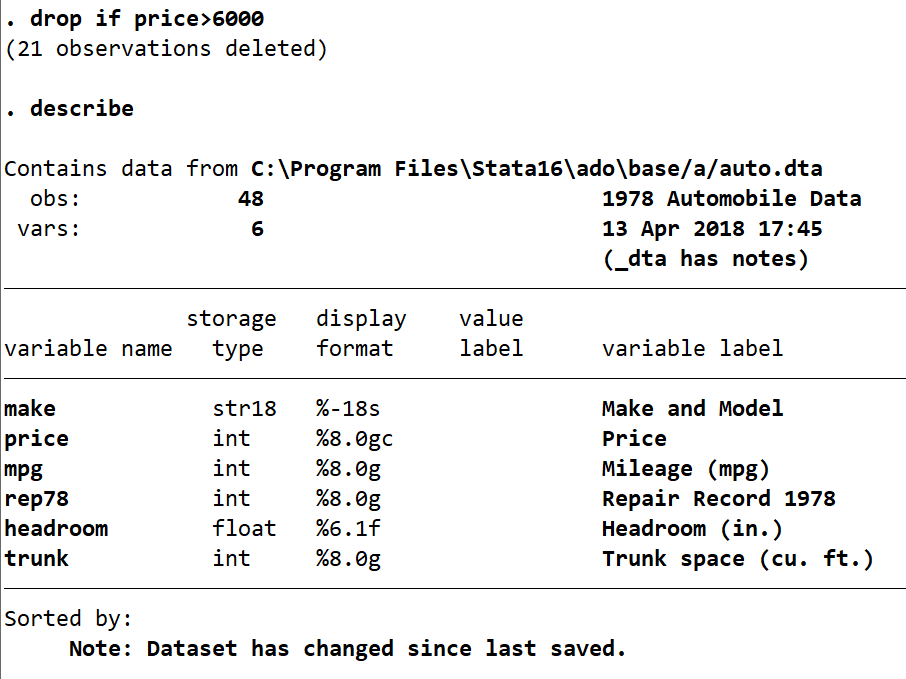
Now Stata tells us we have deleted another 21 observations, which we can confirm by looking at the number of observations listed by describe, which is now obs: 48.
Worked Example 2:
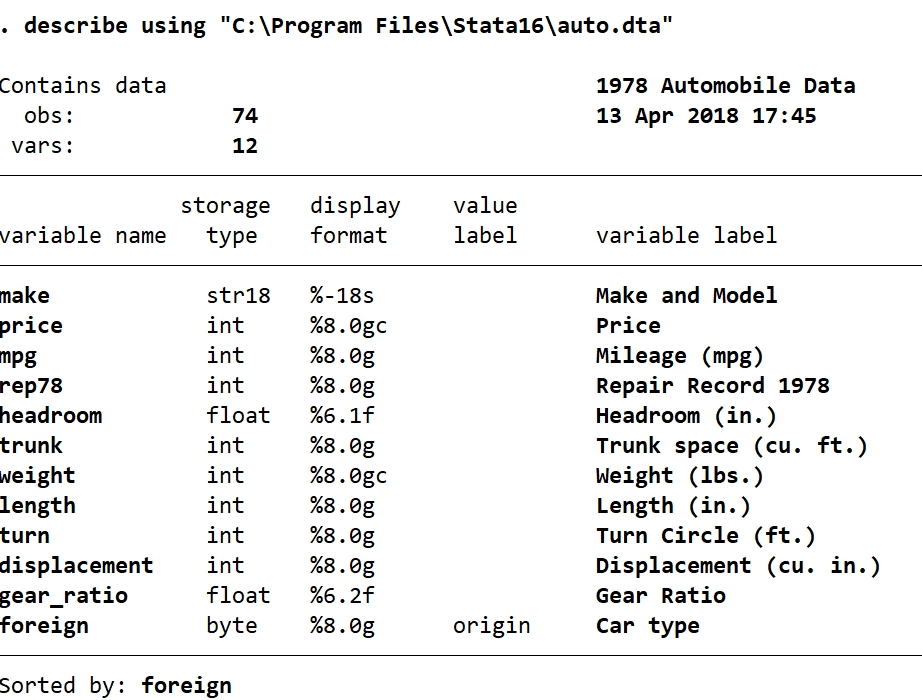
In this example I will demonstrate using the use command to subset your data. This requires an understanding of the data you are working with. We will use the auto dataset as we got an overview of what was in this data through our first example. I am first going to use describe without loading the dataset, as Stata has the ability to describe a dataset that is not yet loaded in memory. I am then going to partially load the dataset from its location on my hard drive, choosing to load only the variables and observations I want. I will use the same 6 variables as before, while at the same time specifying no missing rep78 observations and no observations where price is greater than $6000. With the use command I can do this all at once. In the command pane I type the following:
sysuse auto, clear
save "C:\Users\Laura\Desktop\auto.dta", replace
describe using "C:\Users\Laura\Desktop\auto.dta"
use make price mpg rep78 headroom trunk if(price<=6000 & rep78!=.) using "C:\Users\Laura\Desktop\auto.dta"
describe
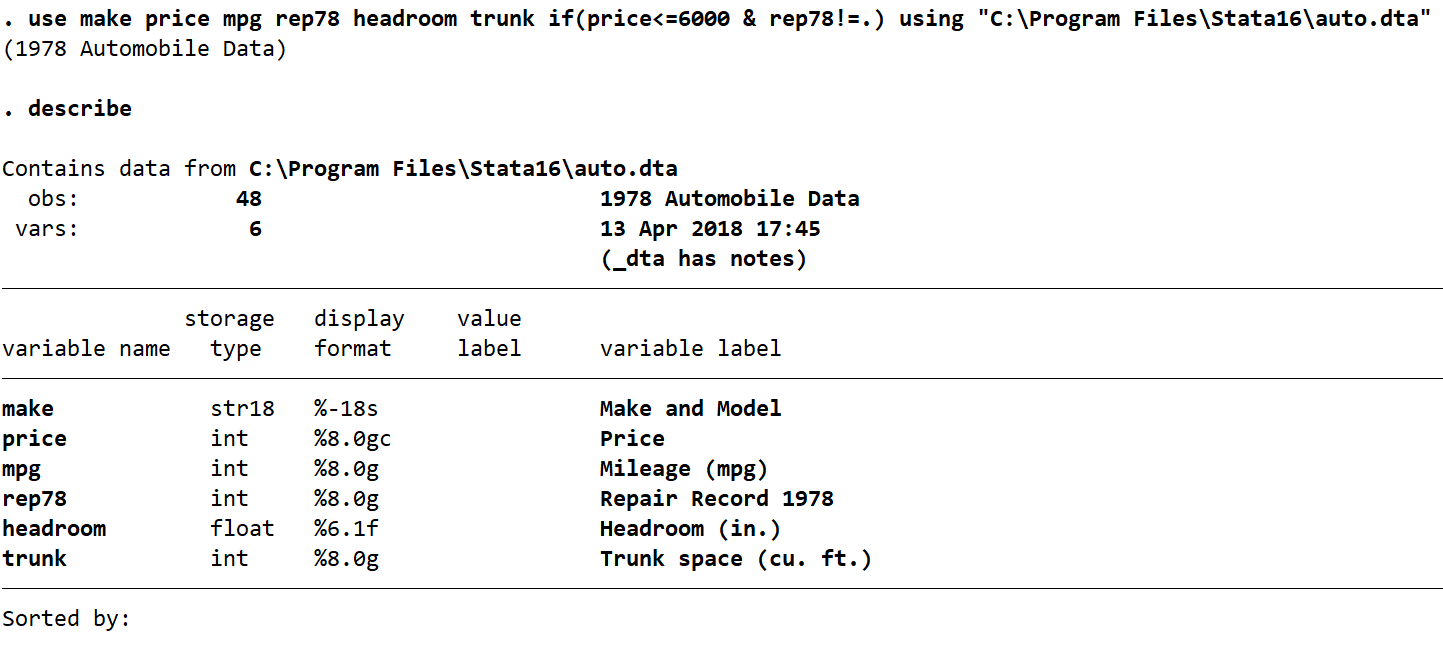
As you can see, the six variables have been brought in, but observations where rep78 is missing or price is greater than 6000 have been left out (not imported). I have done this with one command, without ever loading the full dataset in memory. This is a great tool when you are looking at a really big dataset (e.g. HILDA) and you are only interested in a smaller subset of the data contained in the file. Even if your Stata is unable to load the full dataset, you can still see whats inside it with describe and pull in the bits you need with use.