The estat moran Command - Linear Regression Post-estimation
The estat moran command performs the Moran test for spatial correlation among residuals, also referred to as spatial autocorrelation. The test indicates the amount of similarity between observations at similar spatial locations. When performing a linear regression on spatial data we assume that the observations are independent and identically distributed (i.i.d). The observations should be independently or randomly located. They should not cluster together based on shared properties.
The Moran test for spatial autocorrelation can be used to test whether your linear regression needs to be run with the spregress command and the m1 option, rather than just regress. If the Moran test is statistically significant, you are probably better off running a Spatial AutoRegressive model (SAR) using the spregress command. The Moran test can also be used on individual variables, to determine if a variable is spatially independent (i.i.d).
In order to run the estat moran command you will need to create a spatial weighting matrix to define the error spatial lag to be tested. A spatial weighting matrix represents the spatial structure of your data in a matrix. It is a way to quantify the spatial relationships in your dataset. There are two main types of weighting matrix – binary or variable.
A binary weighting matrix measures the spatial relationship between observations as either 1 or 0. For example, if landmark A is next to landmark B (regardless of the actual distance between the two) then the row/column intersect in the matrix for A and B will be recorded as 1. If landmark D is between landmark A and landmark C, then the row/column intersect of A and C will be recorded as 0, and the intersect of A and D will be 1. An example is shown below, with the locations and then the appropriate binary matrix:


A variable weighting matrix measures the spatial relationship between observations by the amount of impact or influence one observation has on another. The impact or influence can be measured based on the amount of distance between two observation locations.
You use the spmatrix command to create a spatial weighting matrix. Stata offers a binary contiguity matrix or a variable inverse-distance matrix, if your dataset has an attached shapefile. If your dataset does not have an attached shapefile you will need to come up with your own equation which Stata can use to create a spatial weighting matrix specific to your data. We will not cover the creation of specific weighting matrices in this post.
How to Use:
Step 1: Set up your spatial dataset in Stata
EITHER import data from database file (*.dbf) with accompanying shapefile (*.shp) named the same
spshape2dta name_of_file
OR attach a shapefile (*_shp.dta) to an already loaded Stata spatial dataset (*.dta)
spset id_variable
spset, modify shpfile(shape_file_name)
Step 2: Create your spatial matrices (you can use multiple together)
spmatrix create contiguity matrix_name
OR/AND
spmatrix create idistance matrix_name
Step 3: Run a linear regression and the estat moran test
regress var1 var2 var3
estat moran, errorlag(matrix_name)
OR
estat moran, errorlag(matrix_name_1) errorlag(matrix_name_2)
Worked Example 1:
In this example I am going to use a dataset containing the locations of landmarks, which are at various stages in the process of being added to the National Heritage List. This is a dataset that has a database file and a corresponding shapefile, so it is easily converted into Stata datasets using the spshape2dta command. The files are located in my Documents folder, which I set as my current working directory using the cd command. Make sure your database file and shapefile are both located in your current working directory and both have the exact same name, or the spshape2dta command will not import them. The dataset I am using can be found here.
I am going perform a bunch of steps to prepare the data before I can use the regress and estat moran commands. First I will convert the data to Stata datasets with spshape2dta; then load the data into Stata; check the data is correctly loaded as spatial data; rename variables to lowercase; alter a couple of variables from string to categorical using the encode command; create a contiguity spatial matrix; perform a linear regression; and then evaluate that regression using the estat moran command. In the command pane I type the following:
spshape2dta national_heritage_public
use national_heritage_public, clear
spset
rename *, lower
encode class, generate(class2)
encode status, generate(status2)
encode state, generate(state2)
encode source, generate(source2)
drop class status state source
rename (class2 status2 state2 source2) (class status state source)
spmatrix create contiguity nationalc
regress status class state source
estat moran, errorlag(nationalc)
This gives the following output in Stata:




Going through the output, first you can see the spshape2dta command. Stata tells you the files being imported, the new variables being created, and the names of the two new Stata datasets that were created. Following this is the command to load the new Stata dataset, followed by the output from spset, which when run by itself with no options tells you information about the current dataset. Because we used the spshape2dta command the dataset is already set as spatial data. This means spset shows us what type of data we have, the name of the variable containing the spatial unit IDs, the coordinate variables, the type of coordinates (planar), and the name of the attached shape file.
Following spset is a bunch of data management commands I used to prepare the dataset so I can perform a regression. I change all variable names from upper to lower case because that makes the rest of the analysis easier. The variables I am interested in are all categorical, however they are recorded as strings rather than numeric categorical variables. I use encode to convert these string variables to numeric category variables so I can perform linear regression using them.
Once my dataset has been prepared I use the spmatrix command to create a binary contiguity spatial weighting matrix which I call nationalc. I am unable to create an inverse-distance spatial weighting matrix because Stata requires that specific coordinates only be represented once in the dataset. This dataset has some coordinates which are the same for multiple observations and so an inverse-distance weighting matrix cannot be created. If I wanted to use an inverse-distance weighting matrix I would need to drop all observations with duplicate coordinates from the dataset.
Finally, with my dataset ready and my spatial weighting matrix created, I perform a linear regression. Following this regression I perform the estat moran test for spatial correlation among residuals. This gives a p-value of 0.6859, indicating the test was not significant. For this regression our observations are independent and identically distributed, and are consistent with what we expect.
Worked Example 2:
You can also use this test to check if observations in a single individual variable are independent and identically distributed. Simply perform regress with only one variable, and then perform the estat moran test. To demonstrate, I am going to test the “status” variable and then the “state” variable. I would expect the status variable to be spatially independent, however the state variable is really a geographic variable and will likely return a statistically significant test. In the command pane I type the following:
regress status
estat moran, errorlag(nationalc)
regress state
estat moran, errorlag(nationalc)
This gives the following output:
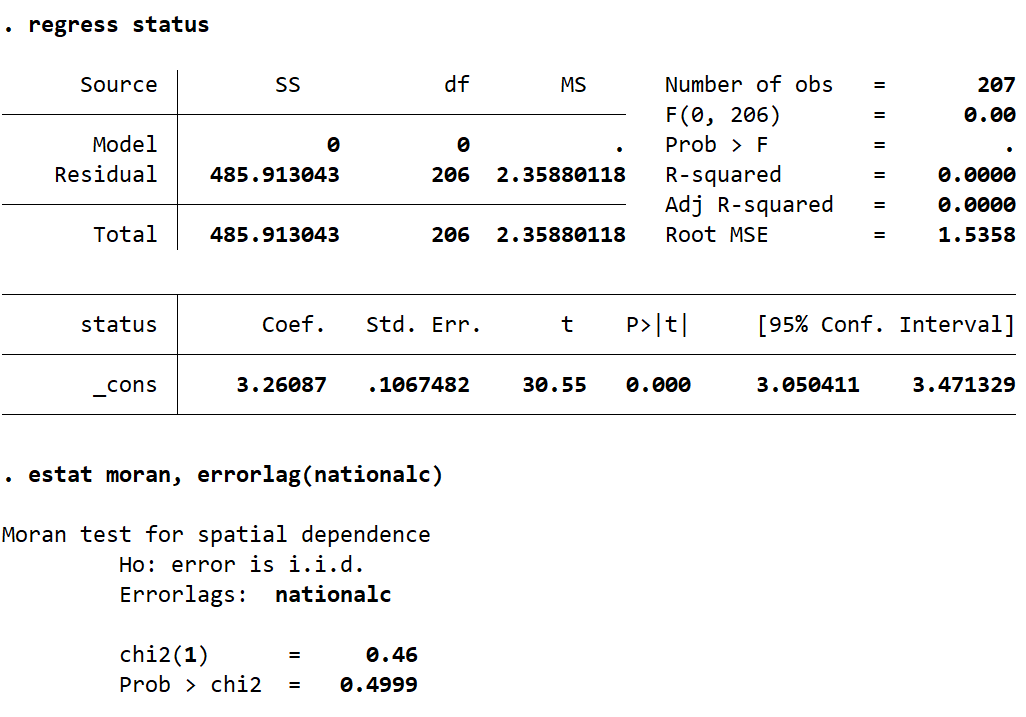

As expected, the status variable gives a not-significant p-value of 0.4999, and the state variable gives a significant p-value of 0.0000*.
*Note: In Stata a p-value of 0.0000 does not mean the p-value was exactly zero. Any p-value of less than 0.00005 is rounded down to 0.0000 in Stata. To find your true p-value in this instance, use the return list command and look for the value assigned to r(p). For this test of the variable “state” the p-value is actually 0.00002246.
The estat moran test is useful for finding spatial autocorrelation in regression models based on spatial data. If this test gives you a statistically significant result for a full regression you should try re-running your regression using the spregress command with the m1 option.
If you use this test on a single variable, consider what outcome you would expect for that variable. In my second example I stated whether or not I expected a significant result for each variable, and the results I got were within those expectations. If I had got a not-significant result for my “state” variable I would be concerned about errors in my dataset. Each state is a separate geographic area of Australia and should not be independently distributed. Observations should be clustered according to state.
On the other hand, if I had got a significant result for my “status” variable this could indicate a bias in the dataset. I would expect approval/disapproval of heritage landmarks to be independent of location. If I found that status was not independently distributed I might be concerned that approval for heritage listing was more likely to occur in some states compared to others.