The Merge Command - Extending Your Dataset Wide
The merge command is used when you have two datasets with different variables linked by common identification variable(s), and you want to combine them into one dataset. For example, you might have a dataset with hotel check-ins, and a separate corresponding dataset with hotel check-outs. These datasets would each have a customer ID variable that was the same for both datasets. The check-in dataset has variables for room number, number of guests, length of stay, main guest name and check-in time. The check-out dataset has total cost, pre-paid or pay on check-out, state of room on check-out, and check-out time. The only variable in common between these datasets is the customer ID variable, and this links observations in the first dataset with observations in the second dataset. If you want to perform analysis on customer stays, it is more useful to have a single dataset that contains all information from both check-in and check-out datasets. This can be easily achieved with a merge (in this case a one-to-one merge).
Note: If you have two datasets that have all or most of the same variables, you probably need to append instead of merge. When appending you are extending your data long, by stacking datasets vertically on top of each other.
There are three main ways to merge datasets in Stata. The first is called a 1:1 (one-to-one) merge, and this is what we would use for our hotel example. This merge is where each observation in the first dataset matches with a single observation in the second dataset. For our hotel example, each match is made by comparing the customer ID variable in each dataset. You can also match using multiple ID variables if your dataset requires this.
The second type of merge is either a m:1 (many-to-one) or a 1:m (one-to-many) merge. This merge is for when you have one dataset with multiple observations per ID variable(s), and another dataset with only one observation per ID variable(s). The single-observation dataset contains information that you want to duplicate within the ID variable(s) for each observation in the multiple-observation dataset. Both 1:m and m:1 are the same merge, the only difference is what dataset you have currently loaded in Stata. If you have your multiple-observation dataset currently loaded then you use a m:1 merge, and if you have your single-observation dataset currently loaded then you use a 1:m merge. The merge itself is the same regardless of which one you use.
The third type of merge is a m:m (many-to-many) merge. This merge is used when you have two datasets each with multiple observations per ID variable(s). These merges are generally not recommended due to the many issues that can arise when you try to use them.
When you perform a merge, Stata creates a new “_merge” variable as part of the merged dataset. This variable indicates whether each observation was successfully merged. A 3 indicates the observation was successfully matched and merged; a 2 indicates the observation was not matched and is only found in the using dataset; and a 1 indicates the observation was not matched and is only found in the master dataset.
How to Use:
merge 1:1 idvariable using filename.dta
merge m:1 idvariable1 idvariable2 using filename.dta
merge 1:m idvariable1 idvariable2 idvariable3 using filename.dta
Worked Example 1 - merge 1:1
In this example I use two fabricated hotel datasets, one called “checkin” and one called “checkout”, with the same information as described earlier. The “checkin” dataset is the one I have currently loaded in Stata. You can download both datasets here: checkin and checkout.
Check-In Dataset:

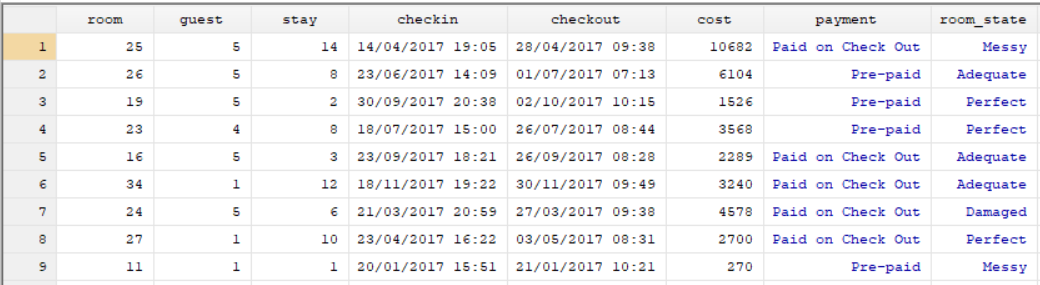
Check-Out Dataset:
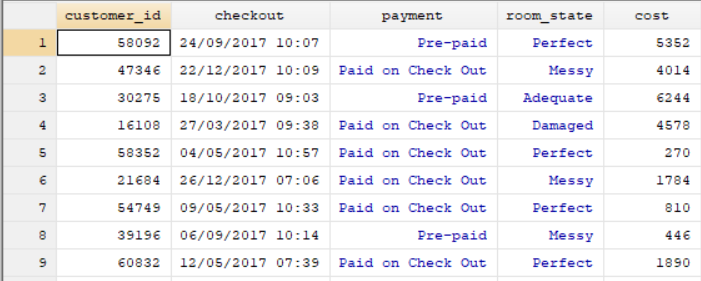
These datasets only have one variable in common, the variable named “customer_id”. This is the ID variable we use to match observations and merge the datasets. In the command pane I type the following:
merge 1:1 customer_id using checkout.dta

As you can see all my observations matched successfully. When you look at the currently loaded dataset again, you’ll see all the variables from both hotel datasets have been merged and an extra variable called “_merge” has been added.
The “_merge” variable indicates whether the observation was successfully merged or not. In my example all my observations matched, so all were marked as 3 in the “_merge” variable. However, not all merges will work perfectly.
Worked Example 2 - m:1
In this example I use two fabricated NSW HSC datasets. The first dataset is called “student_info” and has each students’ id number, name, city of residence, sex, date of birth, and year of graduation. This dataset is the single-observation (1) dataset. The second dataset is called “student_scores” and has multiple different subjects and subject scores recorded for each student id. This dataset is the multiple-observation (m) dataset. For this example, I have the m dataset “student_scores” currently loaded in Stata to allow me to perform a m:1 merge. A 1:m merge here would work the same, you would just have the “student_info” dataset loaded in Stata instead.
You can download the two student datasets here: student info and student scores
Student Info Dataset:
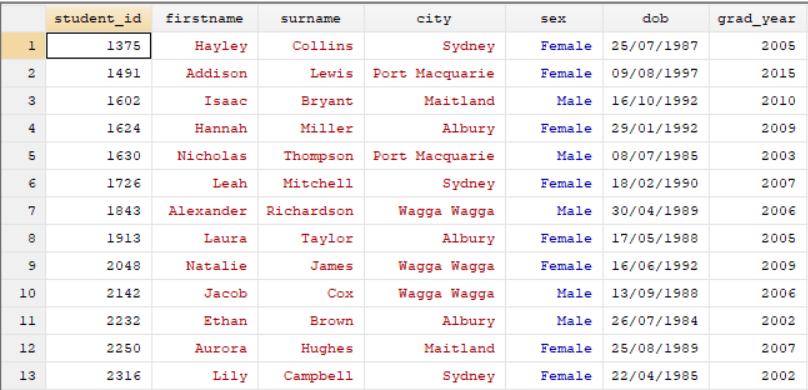
Student Subject Dataset:
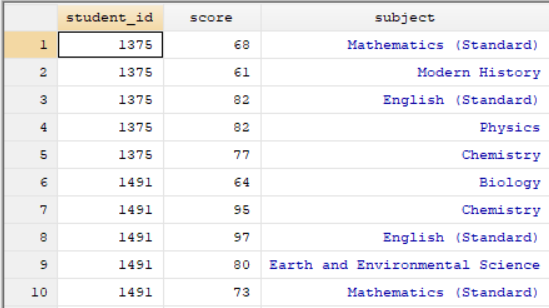
Again these datasets only have one variable in common, the variable named “student_id”. This is the ID variable we use to match observations and merge the datasets. In the command pane I type the following:
merge m:1 student_id using student_info.dta

As you can see all my observations matched successfully. When you look at the currently loaded dataset again, you’ll see all the variables from both hsc datasets have been merged and an extra variable called “_merge” has been added.
Each observation from the “student_info” dataset has been duplicated to match each duplicate observation of student id in the “student_scores” dataset.
Here I have covered two of the three ways to merge datasets in Stata. I will not cover m:m merges here, as they can usually be replaced with a 1:1 or m:1/1:m merge with some modifications to the dataset.