The Reshape Command - Reshape Wide Error: Variable not Constant
The reshape command provides an easy way of moving your dataset between wide and long formats. A simple explanation of wide vs long is that a wide dataset holds all information for an ID variable in a single observation, whereas a long dataset holds information in multiple observations per listed ID. For more information on the basics of reshape, check out our Tech Tip on The Reshape Command.
When you reshape wide you need a “primary ID” variable, a “secondary ID” variable and an “information” variable. Most datasets have many other variables besides these main three, and this is where you can come across the reshape error “variable x not constant within ID_variable”. This error occurs when Stata detects variation in another variable that you have not specified as your “information” variable. Reshape wide assumes that all variables that you do not specify as “information” variables, or as a “secondary ID” variable, will be constant within your “primary ID” variable.
For example, say we have a long dataset which has family surname as the “primary ID” variable, family member number as the “secondary ID” variable, each family member’s age as our “information” variable, and a fourth variable that contains the city each family lives in. The city variable should be the same within the “primary ID” surname variable because all members of the same family live in the same city. When we reshape wide, Stata expects that the city variable will be exactly the same for all observations where a single family surname is listed, because we haven’t specified city as an “information” variable. If however, family_1 has “Melbourne” listed for the Dad and “Sydney” listed for the Mum, the city variable is not constant and you get the error “variable city not constant within primary_ID”.
You can deal with this error in two ways. If the variable is meant to contain variation, add it as another “information” variable to the reshape wide command and Stata will reshape multiple “information” variables from long to wide. If the variable is supposed to be constant and you’ve gotten this error, then you have errors in your data that you’re going to need to fix before you reshape the dataset.
Worked Example:
Below is an example of a dataset I tried to reshape wide where this error occurred. In this case the non-constant variable is supposed to be constant, and the example shows how I chose to deal with the error in order to be able to successfully reshape the dataset.
I have a dataset of NSW HSC results in long format. Each student has their own identification number, which is the “primary ID” variable for this dataset. The “secondary ID” variable in this dataset is the subject variable. This differentiates, within the primary ID variable, which subject the observation is referencing. The “information” variable is the score variable, which contains the score achieved for that subject (secondary ID) for that student (primary ID). All other variables in my dataset should be constant. Each student identification number should always have the same first name, surname, sex, date of birth, graduate year and city.

I’m assuming all the variables besides subject and score are constant within my id variable. This means I can reshape wide. I attempt to do so with the following command code:
reshape wide score, i(id) j(subject)

The error I got tells me my city variable is not constant within my id variable. I already know my city variable is supposed to be constant, so this tells me there are errors in my city variable.
My dataset contains subject scores used to calculate students final HSC and a UAI/ATAR. As such I know that each final HSC score is calculated from 5 subjects, and so each student id number should have 5 duplicate observations, one for each of the 5 subjects used to calculate their HSC. This means each student should have 5 duplicate records of id with city. To check this, I use the duplicates report command.
duplicates report id city

This report shows while the majority of duplicates are 5, there are some with only 3 or 4 duplicates, and some with only 1 or 2 duplicates of id and city. I can use this information to fix the errors in my dataset. In this case I am going to work off a majority-rules basis, so anything that is duplicates of 3 or 4 is the correct city, and anything that is duplicates of 1 or 2 is the incorrect city. My next step is to tag these duplicates so I can identify the errors. I use the duplicates tag command for this.
duplicates tag id city, generate(tag)
This tags observations based on how many duplicates there are of that observation, in this case its only tagging duplicates of id with city. This command tags observations starting at 0, so no duplicates (a single record) is 0, 1 duplicate (2 records that are the same) is 1, etc. I consider anything tagged as 0 or 1 to be an error, and everything else is correct. To fix the errors I am going to remove and then replace the city observation wherever there is a tag of 0 or 1. I start by making the city variable missing if there is a tag of 0 or 1. I drop tag after I’ve used it to erase my errors so it doesn’t get in the way when I reshape again later.
list id city if tag<4
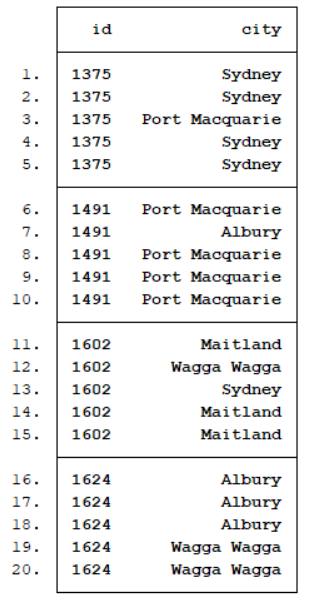
replace city="" if tag <2
drop tag
Now I sort by id, and then use “by id” with the replace command, which allows me to replace missing city observations with non-missing city observations within each individual id.
sort id
by id: replace city=city[_n+1] if missing(city)
by id: replace city=city[_n-1] if missing(city)
We do two versions of the replace city because we are replacing by observation number within each id, which means if we do _n+1 and the observation is the last for that id then the replace won’t occur, so we make sure by also doing an _n-1 replace. To check this has been successful, I do another duplicates report.
duplicates report id city

All my observations are duplicates of 5 in terms of id and city, which is what I expected in the beginning. Now I try the reshape command again, and it should work now.
reshape wide score, i(id) j(subject)

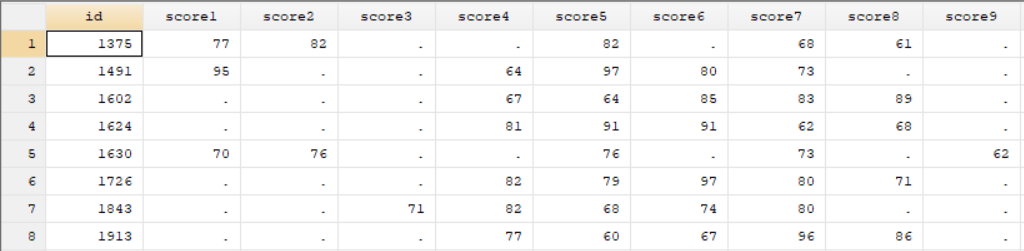
The reshape command has successfully pulled the score variable out into multiple variables. Each score variable represents a subject, and the number after the score stubname is the subject that is represented. I have a separate list so I know what subject each number represents. If I didn’t have a separate list, I could have used decode to turn the variable into a string and used the string option with my reshape command, and this would have added each subject name after score as variable names.
This kind of data management requires a good understanding of your dataset, as well as the Stata syntax you are using to fix problems with your data. For this task I knew what my dataset should look like, and based on this I should have been able to reshape the data from long to wide. When this didn’t work I knew immediately there was an issue with the data, and based on the reshape error I got I knew there were anomalies in my city variable. I also knew what kind of data my dataset contained, which told me that every id should have 5 duplicate city entries. This understanding helped me to create the solution I demonstrated above.
If I had a different dataset where the number of duplicate id observations differed per id, then I would have needed a different solution to this problem. The basic use of the duplicates command could still work, provided I am still assuming anything tagged as 0 is wrong. I would suggest looking at the expand command with the generate option in this instance as well, to make sure if you change a variable to missing, you still have something to copy back to it if there really was only one instance of that id observation. Otherwise you risk losing some data.
The way you deal with errors will depend on what the error is and what your dataset is supposed to look like, so always make sure you have a good understanding of what’s supposed to be there, and what isn’t.