The Sort and Order Commands
The sort and order commands are useful for organising your data so it is easier to analyse and you can see patterns more easily.
The sort command orders the observations in ascending order according to the specified variable(s). If you specify more than one variable, the data is first sorted on the first variable, and then within those observation categories of the first variable they are sorted on the second variable. It assumes all observations in a row are mutually exclusive.
The order command relocates a variable to another place in the dataset. You can put a variable (column) at the beginning or end of the dataset, as well as before or after another variable in the dataset. The default for this command is to move the variable to the beginning of the dataset.
How to Use:
sort var1
sort var1 var2
order var1
order var1, last
order var1, before(var2)
order var1, after(var2)
Worked Example:
I will use the auto dataset to demonstrate the sort and order commands. I will first use the list command to have a look at how my two variables are set up prior to sorting and ordering. In the command pane I type the following:
sysuse auto, clear
describe
list make rep78 in 1/10
This gives me the following output:
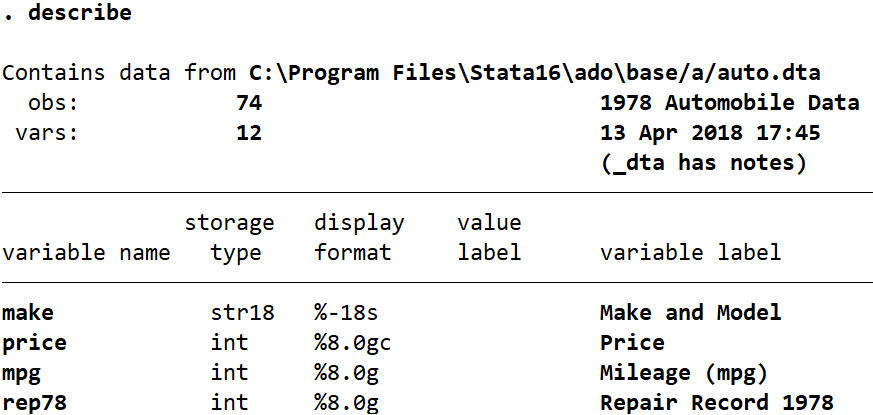

The describe command allows me to see the current order of my variables, and the list command with an [in range] qualifier shows me the current order of the first 10 observations in my dataset. I am now going to use the sort and order commands to alter the order of my variables and observations. In the command pane I type the following:
order rep78, after(make)
sort rep78 make
describe
list make rep78 in 1/10


You can see by comparing the describe and list outputs with each other the changes that have occurred. In the first describe the order of variables is “make price rep78 mpg”, and in the second it has changed to “make rep78 price mpg”. This change is due to the order command. In the first list we see the observations appear ordered alphabetically based on the “make” variable. In the second list the order of observations has changed to be in order of “rep78” values (from 1 to 5), with observations further ordered alphabetically by “make” within each category of “rep78”. So now the cars with a repair record of 1 all appear at the top, and they are all in alphabetical order.
Note: There are some observations in this dataset that are missing “rep78”. Stata treats all missing values as being larger than any other value in the dataset. For this reason, if you examine the auto dataset after it has been sorted above, you will find the cars that are missing “rep78” are all at the bottom of the dataset.