The lvr2plot Command - Linear Regression Post-Estimation Plots
The lvr2plot command plots leverage against normalized squared residuals. It is sometimes also called an L-R plot. Use this plot after a linear regression, to help identify individual observations that have an abnormally high leverage or large residuals.
This plots leverage on the Y-axis, and normalized squared residuals on the X-axis. The vertical red line represents the average normalized squared residuals across the dataset. Observations to the right of this line have above average squared residuals and may need further investigation. The horizontal red line represents the average leverage across the dataset. Observations above this line have above average leverage and may need further investigation.
An observation with high leverage is one that has no close neighbouring observations. Because this lonely value has no neighbours it will naturally pull the regression line towards it, influencing the slope of the line. These highly influential observations can affect the trueness of your regression line, and may need to be removed to get a more accurate model.
An observation with a large squared residual indicates that the predicted value based on the regression line was a lot higher or a lot lower than the actual observed value. This indicates outliers in the data. An outlier should be further investigated for potential issues, such as incorrect data, and if an issue with the outlier is found it should be rectified or the outlier removed from the model. However, you should be careful about excluding outliers purely to obtain a better model.
How to Use:
*Run a linear regression, then
lvr2plot
OR to label the plot points
lvr2plot, mlabel(label_variable)
Worked Example:
In this example I will run a simple linear regression using the Stata auto example dataset. I will then use the lvr2plot command to help identify observations with unusually high leverage or squared residuals. In the command pane I type the following:
sysuse auto, clear
regress price turn
lvr2plot
This generates the following graph in Stata:
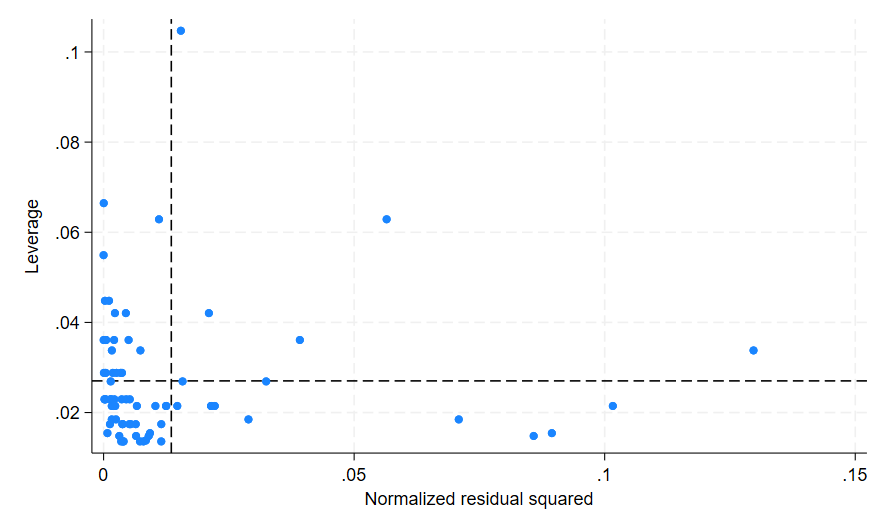
In this plot I can see a few issues. There is one observation with a very high leverage value, at the top left of the graph. There are also five observations with high residual values, at the bottom right and bottom middle of the graph. I am not particularly concerned about the observation in the middle of the graph, as while it has both high leverage and high residuals, the values are not too far above the average to be concerning. While there are no observations on this graph in the top right quarter, any observations found in that quarter would have both very high residuals and very high leverage. If you generate an lvr2plot that has points in the top right quarter you should pay special attention to those observations.
In total I have identified six observations that I would like to investigate further, however I do not know which observations they are. To find out what observations I am looking at I add the mlabel() option with the make variable, as this variable is able to individually identify each observation so I am able to identify them. If your dataset does not have a variable that can identify observations individually from each other you can create a variable containing the observation number itself which will identify the observations individually for you.
In the command pane:
lvr2plot, mlabel(make)
This produces the following modified lvr2plot graph:
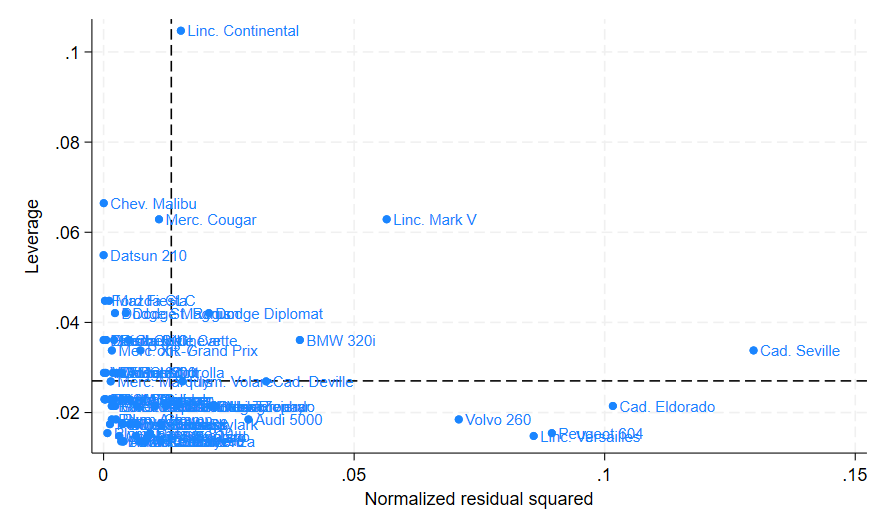
From this modified graph I am able to determine the six observations as the “Linc. Continental”, “Volvo 260”, “Peugeot 604”, “Linc. Versailles”, “Cad. Eldorado”, and “Cad. Seville”. Let’s see if I can improve my regression model by removing these six observations. In the command pane:
generate dummy = 0
replace dummy = 1 if make == "Linc. Continental" | make == "Volvo 260" | make == "Peugeot 604" | make == "Linc. Versailles" | make == "Cad. Eldorado" | make == "Cad. Seville"
regress price turn if dummy == 0
lvr2plot
This creates the following graph:
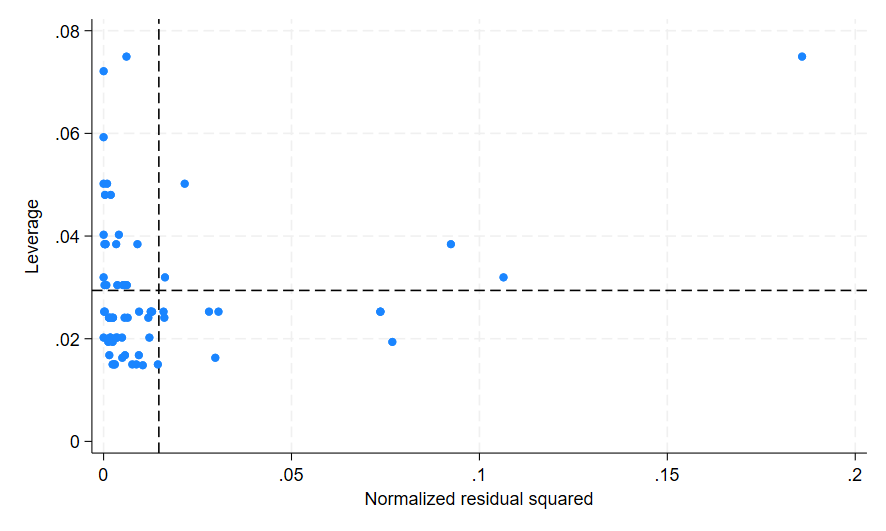
There are several things to note here. The first is that once I removed those six observations, the R-squared value for the regression decreased from 0.0959 to 0.0259. The R-squared value indicates the amount of variance that is explained by the model, and while 0.0959 is already a very low R-squared value, the decrease to 0.0259 is significant. The R-squared value for this model is now almost negligible, indicating our model is a bad fit to the data.
When removing highly influential observations or outliers from a regression, we can expect our R-squared value to be impacted. While the R-squared may increase or decrease, the result will be a more accurate indication of the fit of the model. In this case because our R-squared value decreased, this indicates that there were only a few observations that were propping up the model and making it appear better than it really was. Conversely when the R-squared value increases after influential observations or outliers are removed we can infer that those observations were depressing our model, making it fit worse than it otherwise would.
The second thing to note is that our graph still appears to have high leverage and high residual values. As both the Y-axis and the X-axis scales are similar to those in the original graph, this indicates there is a bigger problem with my model than just a few outliers. In this instance the low R-squared value indicates this model is not a very good fit for my chosen variables, however you may encounter other issues with your model as you investigate it.
The lvr2plot command can be used together with the dfbeta command and the predict command influence statistics to identify problematic observations for further investigation.